La computer vision ou vision par ordinateur est la capacité d’un système informatique à interpréter des informations visuelles contenues dans des vidéos et images.
L’enjeu est que cette « vision » soit nourrie par une connaissance humaine et capable d’identifier certaines situations avec une connaissance métier.
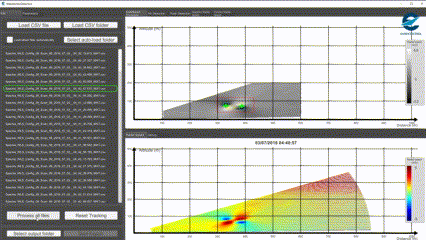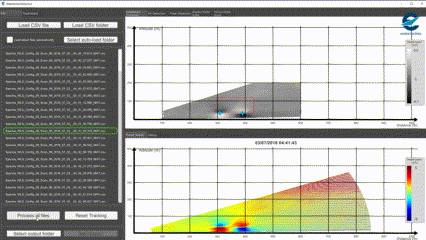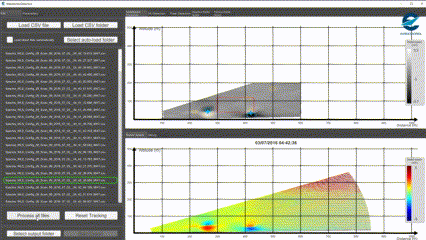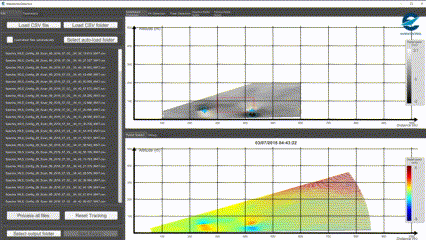
Il s’agit donc de partir de certains données brutes visuelles pour les traduire dans des contextes d’interprétation humaine particuliers. Dans ce projet fait avec Eurocontrol, nous travaillons par exemple à identifier, dans des relevés LIDAR, des paterns visuels caractéristiques des turbulences de sillage dans le secteur aérien (avec Open CV entre aures).
Détection de patern dans un relevé Lidar, Octarina pour Eurocontrol
Parmi les nombreux domaines d’applications se trouvent les véhicules autonomes ou bien sur la computer vision est enjeu essentiel pour l’avenir de l’automobile.
Mais aussi le contrôle qualité, l’aide à la maintenance – à coupler à de la réalité augmentée à l’avenir.
Pourquoi le deep learning a considérablement fait
évoluer la computer vision ?
L’exemple de Tesla est significatif. En effet, lors des récents Tesla AI Days ont été présentées toutes les technologies liées à la conduite autonome.
Ou l’on voit que le volume de connaissance et d’interprétation à transmettre au véhicule est énorme.
En effet, si nous humains profitons de notre expérience de vie pour acquérir des connaissances, il n’est pas de même pour la machine qui part “à vide”. Il faut donc lui apprendre à travers des réseaux neuronaux qui imitent le comportement de notre cerveau.
C’est cette phase d’apprentissage machine ou deep learning qui reste une étape cruciale en terme qualitatif et colossal en terme de volume de travail.
A tel point que Tesla se dote de supercalculateur et d’une puce spéciale, DOJO, dédiée à l’entraînement machine.
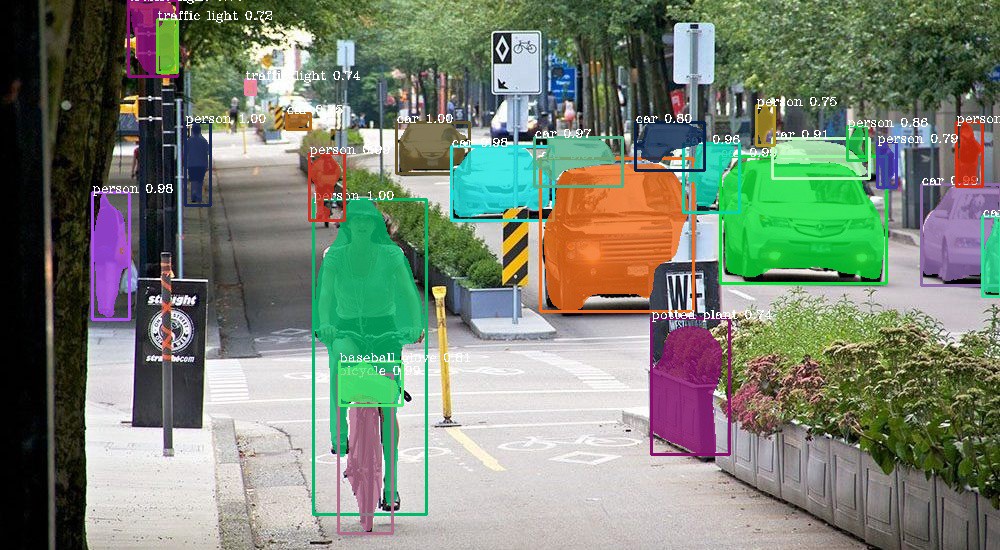
Il faut savoir que cet entraînement machine est très laborieux. D’une part pour la constitution du jeu de données. Cela consiste à labéliser des millions d’images. A savoir détourer chaque catégorie d’éléments dans les images et à les catégoriser : personne, voiture, etc.
Image labellisée
D’autre part, le deep learning est très gourmand en ressources GPU. Une fois le data set finalisé, il faut entraîner le réseau neuronal correctement sans le surentraîner. Tesla a d’ailleurs utilisé des logiciels de simulation 3D pour créer des data sets automatiquement labélisés. Pour une question de productivité mais aussi pour créer des cas difficiles à trouver sans prendre risque (personnes qui courent sur l’autoroute) ou à labéliser (trop de piétons à la fois).
Labélisation difficiles. Source: Tesla
Et si vous voulez savoir pourquoi nous pensons que cette approche est l’avenir de la réalité augmentée c’est ici
Nous créons des datasets et entrainons des réseaux neuronaux pour vos propres besoins, n’hésitez pas à nous contacter.